AI-Powered Rules as Code: Experiments with Public Benefits Policy: Summary + Key Takeaways
This is the summary version of a report that documents four experiments exploring if AI can be used to expedite the translation of SNAP and Medicaid policies into software code for implementation in public benefits eligibility and enrollment systems under a Rules as Code approach.


This publication is a summary of the AI-Powered Rules as Code: Experiments with Public Benefits Policy report.
Introduction
The rise of commercially-available large language models (LLMs) presents an opportunity to use artificial intelligence (AI) to expedite the translation of policies into software code for implementation in public benefits eligibility and enrollment systems under a Rules as Code approach. Our team experimented with multiple LLMs and methodologies to determine how well the LLMs could translate Supplemental Nutrition Assistance Program (SNAP) and Medicaid policies across seven different states. We present our findings in this report.
We conducted initial experiments from June to September 2024 during the Policy2Code Prototyping Challenge. The challenge was hosted by the Digital Benefits Network and the Massive Data Institute, as part of the Rule as Code Community of Practice. Twelve teams from the U.S. and Canada participated in the resulting Policy2Code Demo Day. We finished running the experiments and completing the analysis from October 2024 to February 2025.
In this report and summary you will learn more about key takeaways including:
- LLMs can help support the Rules as Code pipeline. LLMs can extract programmable rules from policy by leveraging expert knowledge retrieved from policy documents and employing well-crafted templates.
- LLMs achieve better policy-to-code conversion when prompts are detailed and the policy logic is simple.
- State governments can make it easier for LLMs to use their policies by making them digitally accessible.
- Humans must be in the loop to review outputs from LLMs. Accuracy and equity considerations must outweigh efficiency in high-stakes benefits systems.
- Current web-based chatbots have mixed results, often risking incorrect information presented in a confident tone..
Current State: Policy from Federal and State Government
Public benefits in the United States are governed by a complex network of federal, state, territorial, tribal, and local entities. Governments enact a web of intersecting laws, regulations, and policies related to these programs. These are often communicated in lengthy and complex PDFs and documents distributed across disparate websites. Maintaining eligibility rules for public benefits across eligibility screeners, enrollment systems, and policy analysis tools—like calculating criteria for household size, income, and expenses—is already a significant cross-sector challenge. This complexity hinders government administrators’ ability to deliver benefits effectively and makes it difficult for residents to understand their eligibility.
We have heard directly from state and local government practitioners about the challenges with their eligibility and enrollment systems and how they intersect with policy. For example, one state practitioner described it as “a scramble” to update the code in legacy systems. Implementation is often completed by a policy team, technology team, or external vendor, which increases the potential for errors or inconsistencies when system changes or updates are needed. An additional challenge is that no U.S. government agency currently makes its eligibility code open source, which ultimately reduces transparency and adaptation across other government systems.
Introduction to Rules as Code
Adopting Rules as Code for public benefits is a crucial strategy to improve the connection between policy and digital service delivery in the U.S. The Organization for Economic Co-operation and Development (OECD) defines Rules as Code as “an official version of rules (e.g. laws and regulations) in a machine-consumable form, which allows rules to be understood and actioned by computer systems in a consistent way.” Using Rules as Code in expert systems and automated or semi-automated decision-making systems is a key use case.
This approach facilitates seamless and transparent policy integration into standardized public benefits delivery systems. A state leader noted that Rules as Code supports a “no wrong door” vision, ensuring consistent eligibility criteria across all service entry points, or “doors.”
In a future Rules as Code approach to benefits eligibility, policies and regulations would be translated into both plain-language logic flows (pseudocode) and standardized, machine-readable formats, such as Extensible Markup Language (XML), JavaScript Object Notation (JSON), or Yet Another Markup Language (YAML). This would enable easy access by various systems, including benefits applications, eligibility screeners, and policy analysis tools. Doing this would enable stakeholders to simultaneously review the legislation or regulation, plain language logic, and code, and know that all are official and ready for implementation. Ideally, this would also enable a more seamless cycle of writing, testing, and revising the rules. Others have written about the challenges and consequences of implementing Rules as Code, including an in-depth analysis of work in New Zealand, and a lawyer and programmer’s recreation of government system code for French housing benefits.
Figure 1*: Benefits Eligibility Rules as Code
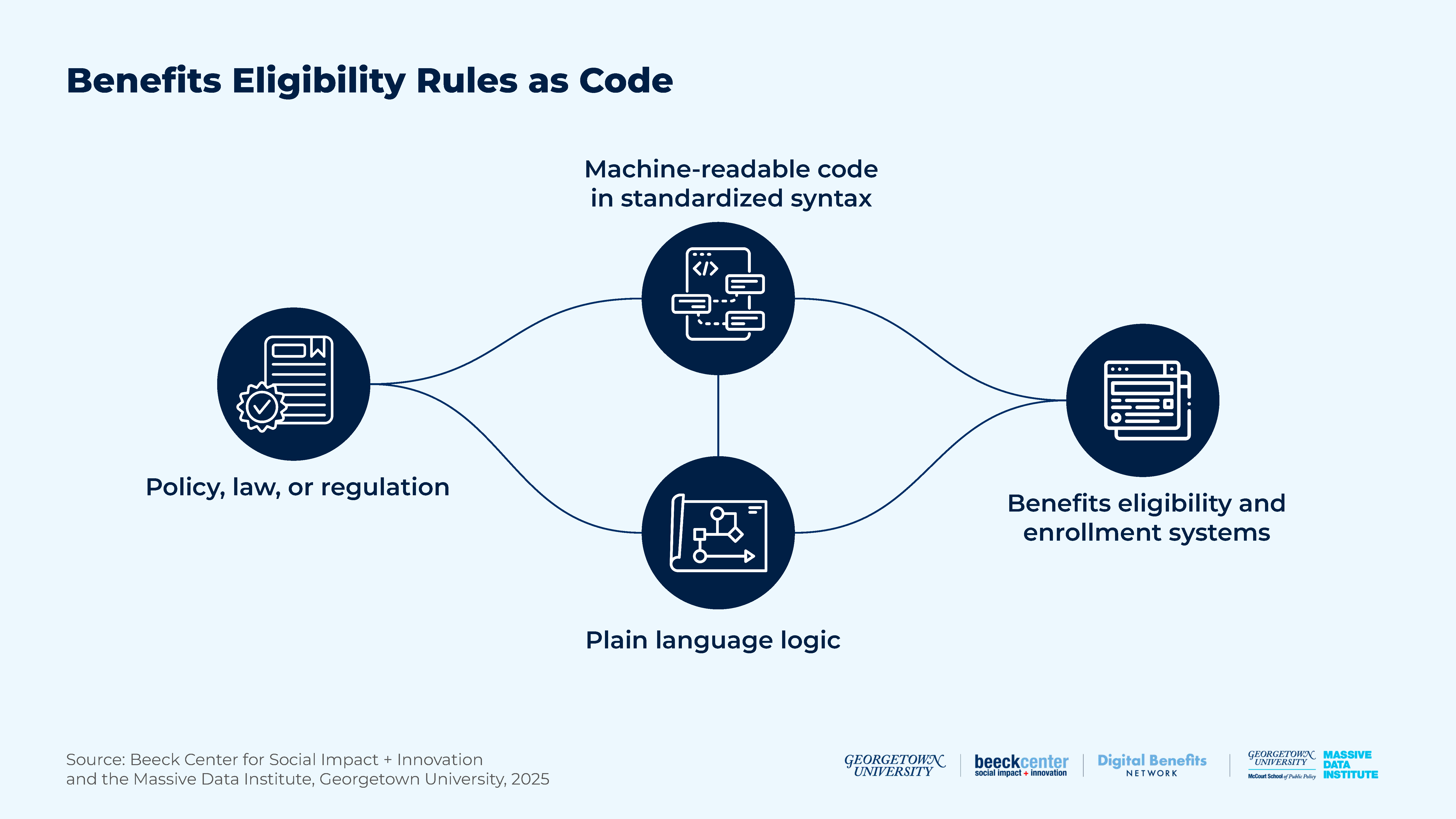
There is a vibrant ecosystem of organizations that have already created online eligibility screening tools, benefits applications, policy analysis tools, and open-source resources across numerous public benefits programs. These organizations play a crucial role in increasing access to benefits for eligible individuals, and several serve as tangible examples of how open, standardized code can translate policy into system rules.
In addition to open-code bases, there are other frameworks that can inform the standardization of communicating Rules as Code for U.S. public benefits programs. To reduce time and money spent on creating new frameworks, we believe it is important to evaluate and test any existing frameworks or standards to determine if they can be adopted or further developed.
Introduction to Generative AI
Artificial intelligence (AI) is the science of developing intelligent machines. Machine learning is a branch of AI that learns to make predictions based on training data. Deep learning is a specific type of machine learning, inspired by the human brain, that uses artificial neural networks to make predictions. The goal is for each node in the network to process information in a way that imitates a neuron in the brain. The more layers of artificial neurons in the network, the more patterns the neural network is able to learn and use for prediction.
Many successful generative AI tools and applications are designed using deep learning models. A large difference between classic machine learning and generative AI is that generative AI models not only identify patterns that they have learned, but also generate new content. One specific type of deep learning model for processing human text is Large Language Models (LLMs). The goal of LLMs is to attempt to capture the relationship between words and phrases. LLMs have been trained using enormous amounts of text and have human-like language ability across a range of traditional language tasks. However, it remains unclear how well different LLMs and tools built using LLMs—e.g. chatbots—work in more complex, domain-specific prediction tasks, like Rules as Code.
Intersection of Generative AI with Rules as Code
As the use of automated and generative AI tools increases and more software attempts to translate benefits policies into code, the existing pain points will likely be exacerbated. To increase access for eligible individuals and ensure system accuracy, it is imperative to quickly build a better understanding of how generative AI technologies can, or cannot, aid in the translation and standardization of eligibility rules in software code for these vital public benefits programs. We see a critical opportunity to create open, foundational resources for benefits eligibility logic that can inform new AI technologies and ensure that they are correctly interpreting benefits policies.
If generative AI tools are able to effectively translate public policy or program rules into code and/or convert code between software languages, it could:
- Speed up a necessary digital transformation to Rules as Code;
- Allow for humans to check for accuracy and act as logic and code reviewers instead of programmers;
- Automate testing to validate code;
- Allow for easier implementation of updates and changes to rules;
- Create more transparency in how rules operate in digital systems;
- Increase efficiency by eliminating duplicate efforts across multiple levels of government and delivery organizations; and
- Reduce the burden on public employees administering and delivering benefits.
Additionally, once rules are in code, it could enable new pathways for policymakers, legislators, administrators, and the public to model and measure the impacts of policy changes. For example, a generative AI tool could help model different scenarios for a rules change, using de-identified or synthetic data to measure impact on a specific population or geography. Additionally, generative AI can also help governments migrate code from legacy systems and translate it into modern code languages or syntaxes, as well as enable interoperability between systems.
Overview of Experiments
We designed four experiments to test commercially-available LLMs in translating policies into plain language summaries, machine-readable pseudocode, or usable code within a Rules as Code process. In the full report, we detail the methodologies, findings, and considerations for public benefit use cases. Additionally, we provide openly accessible materials including rubrics, prompts, responses, and scores for each experiment.
| Policy Focus | States | Technology Focus |
|---|---|---|
| SNAP and Medicaid | SNAP and Medicaid: California, Georgia, Michigan, Pennsylvania, and Texas SNAP only: Alaska Medicaid only: Oklahoma | API: GPT-4o Web browser AI chatbots: ChatGPT (GPT 3.5 )and Gemini (Gemini 1.5 Flash) |
Experiment 1: Asking Chatbots About Benefits Eligibility
How well can LLM chatbots answer general SNAP and Medicaid eligibility questions based on their training data and/or resources available on the internet? What factors affect their responses?
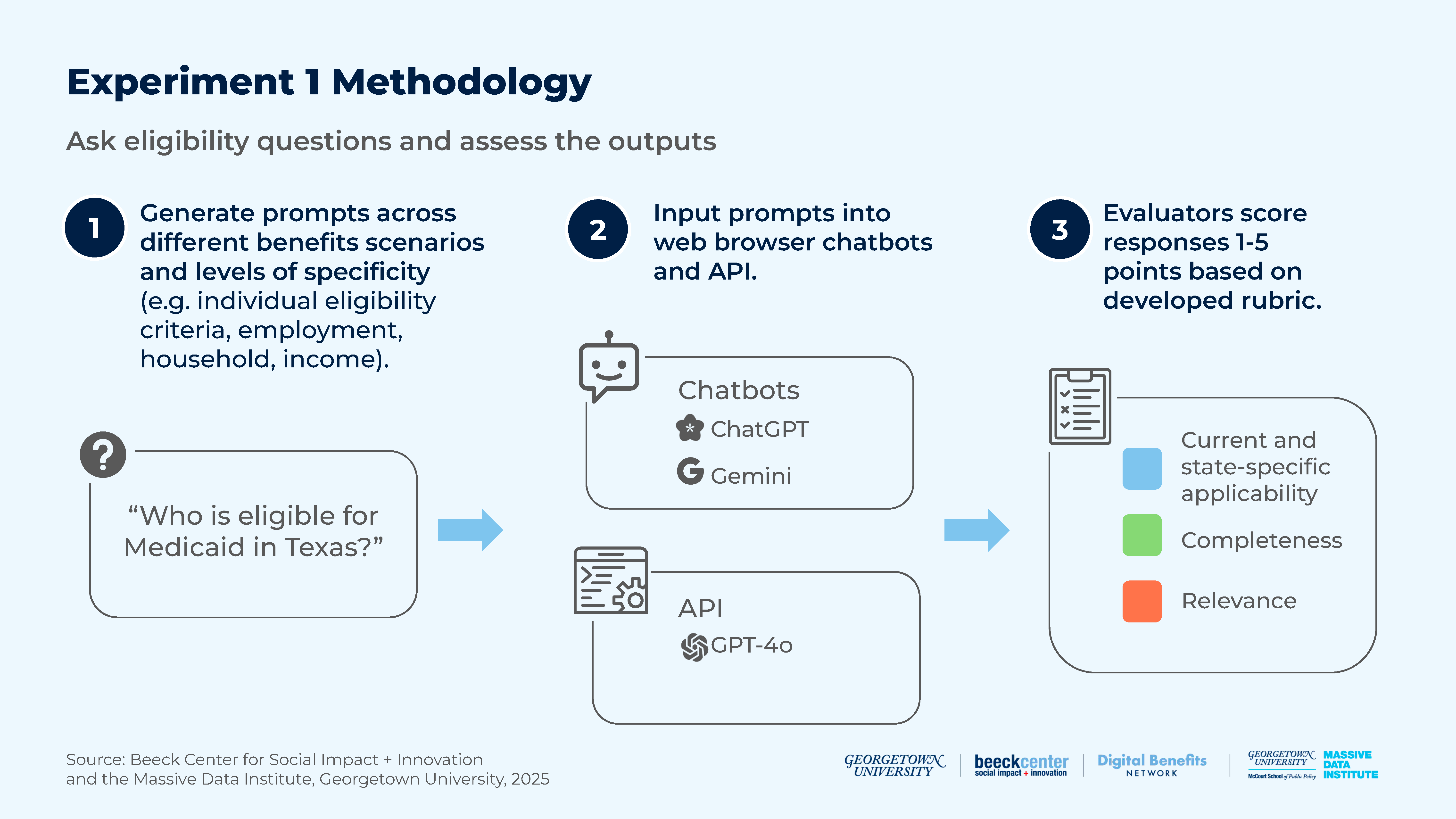
We tested how three LLMs—the web browser versions of ChatGPT and Gemini, as well as the GPT-4o API—extracted and provided information about eligibility for different policies.
For this experiment, our research group analyzed and scored the responses generated by the LLMs for state-specific and current applicability, relevance, and completeness.
Figure 2: Experiment 1 Methodology
Notable Results & Considerations
- LLMs were less effective when asked to identify all of the eligibility criteria for SNAP or Medicaid in a single query, compared to when asked to identify the details of each individual criterion for eligibility in a single query. (Table 3)
- There were no major differences in the three models’ performances.
Figure 3: Model Effectiveness
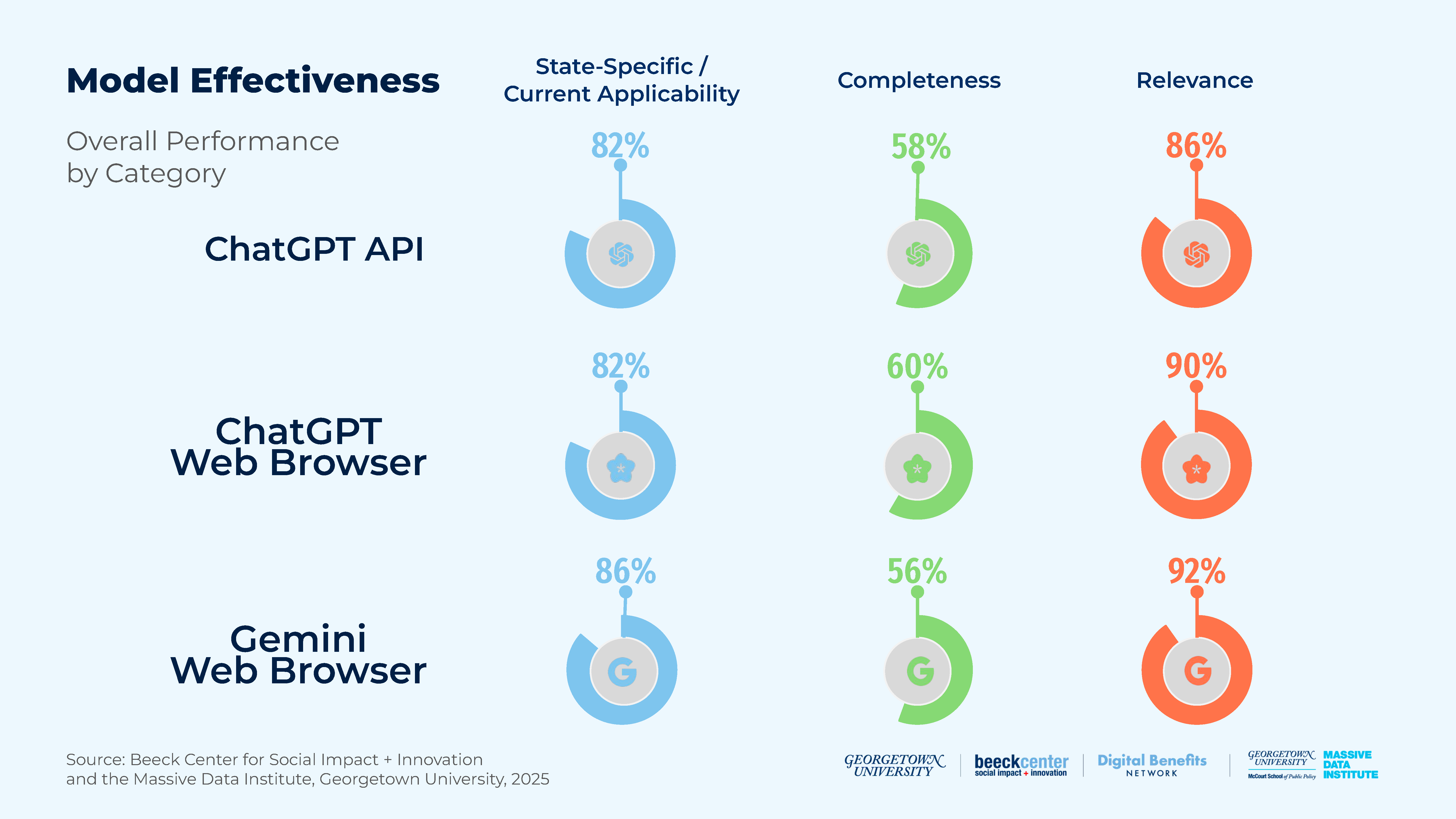
- The average scores for Medicaid responses were slightly higher than for SNAP responses across all three rubric criteria. (Table 5)
- See the full experiment for prompts and scores for each LLM by state and program.
Experiment 2: Focusing LLMs on Specific Benefits Policy Documents
How well can an LLM generate accurate, complete, and logical summaries of benefits policy rules when provided official policy documents?
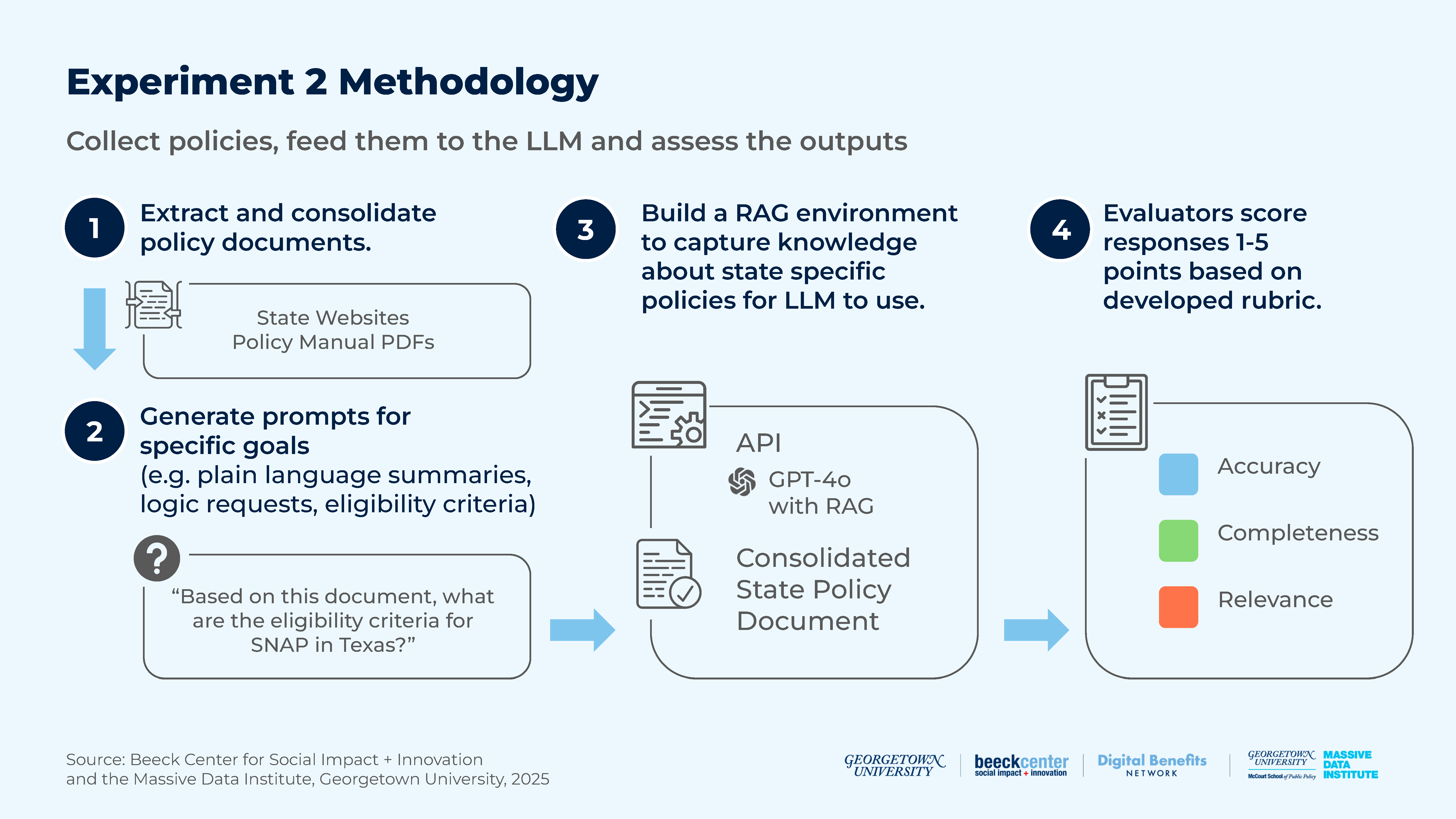
For Experiment 2, we used Retrieval-Augmented Generation (RAG), a technique that allowed an LLM to use not only its training data to respond to queries, but also knowledge from authoritative sources provided by the user — in this case authoritative benefits program policy documents.
We tested how well the GPT-4o API generates accurate, complete, and logical summaries of benefits policy rules in response to different types of prompts.
Figure 8: Experiment 2 Methodology
Notable Results & Considerations
Figure 9: GPT-4o API Performance by Category by State and Program
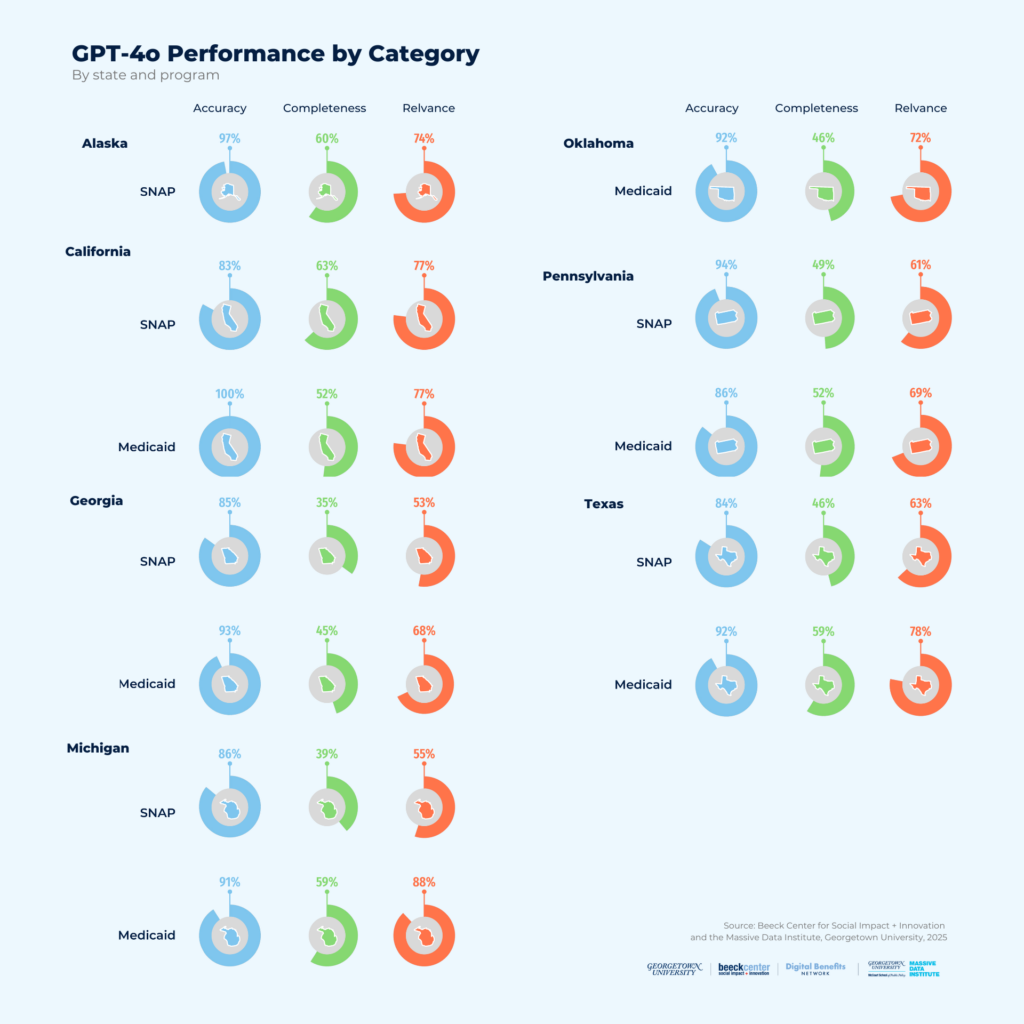
- A key challenge we encountered was the fragmentation across PDFs and websites for current legislative documents or policy manuals for each state. State governments can make it easier for LLMs to use their policies by making them digitally accessible. At a minimum, this means a single PDF that allows text extraction; even better is a plain text or HTML document, or a webpage presenting the policy in full, including the effective date. Read observations about the specific documents we used for SNAP (Table 14) and Medicaid (Table 15).
- Focusing LLMs on specific policy documents increases accuracy in responses, but results are mixed for relevance and completeness. Simply pointing an LLM to an authoritative document does not mean it will pull out the relevant information from the document. A more promising direction may be to consider one of the following: custom-designed RAG document collections, fine-tuning with labeled data, or newer reinforcement learning approaches that automatically attempt to identify the relevant information for the query. Additionally, the way policy documents are written and structured—such as including specific eligibility criteria tables—can also improve LLM performance.
- When given prompts for either SNAP or Medicaid, we found that the GPT-4o API generally returns accurate results; however, scores drop off significantly for completeness and relevance. This means that while the response may be accurate, it is likely missing information that would help inform an action or decision about SNAP or Medicaid. The response may also include information that is not relevant to the prompt, making it less useful for assessing eligibility. (Table 16 & Table 17)
- See the full experiment for detailed results, sample prompts, case studies on accuracy, relevance, and completeness trends for Georgia SNAP and Oklahoma Medicaid, and comparison of prompt effectiveness for SNAP and Medicaid across states.
Experiment 3: Using LLMs to Generate Machine-Readable Rules
How well can an LLM extract machine-readable rules from unstructured policy documents in terms of output relevance and accuracy? How does the use of a structured rules template impact an LLM’s ability to produce relevant and accurate output?
Our task in this experiment involved prompting the LLM (GPT-4o) to populate the predefined rules with corresponding values based on a specified program and state. The goal was to compare the ability of readily available LLMs and LLMs with additional external knowledge (e.g. RAG) to generate programmatic policy rules.
We considered a direct query approach that was unsuccessful and led to an experimental design that began by compiling a Rules Template, where we assembled a predefined set of policy rules in a structured JSON format. These rules were selected based on their common applicability across different programs and state-specific variations in our case studies.
Figure 15: Experiment 3 Methodology

Initial attempts to prompt the LLM to directly identify rules from policy documents proved unreliable, as outputs were highly sensitive to prompt phrasing. We came to the conclusion that the LLM struggled to produce dependable and uniform results without a strictly-defined rules template. We conducted the remaining experiments with a manually-curated rules template for both SNAP and Medicaid across six states. For SNAP, the rules included criteria such as income limits based on family size, citizenship requirements, and other key eligibility conditions. For Medicaid, the rules incorporated covered groups (e.g., pregnant women, low-income families) and age requirements, among other criteria.
Figure 14: Simplified SNAP Rules Template

Notable Results & Considerations
Figure 16: Average Rules Generation Accuracy by State and Category
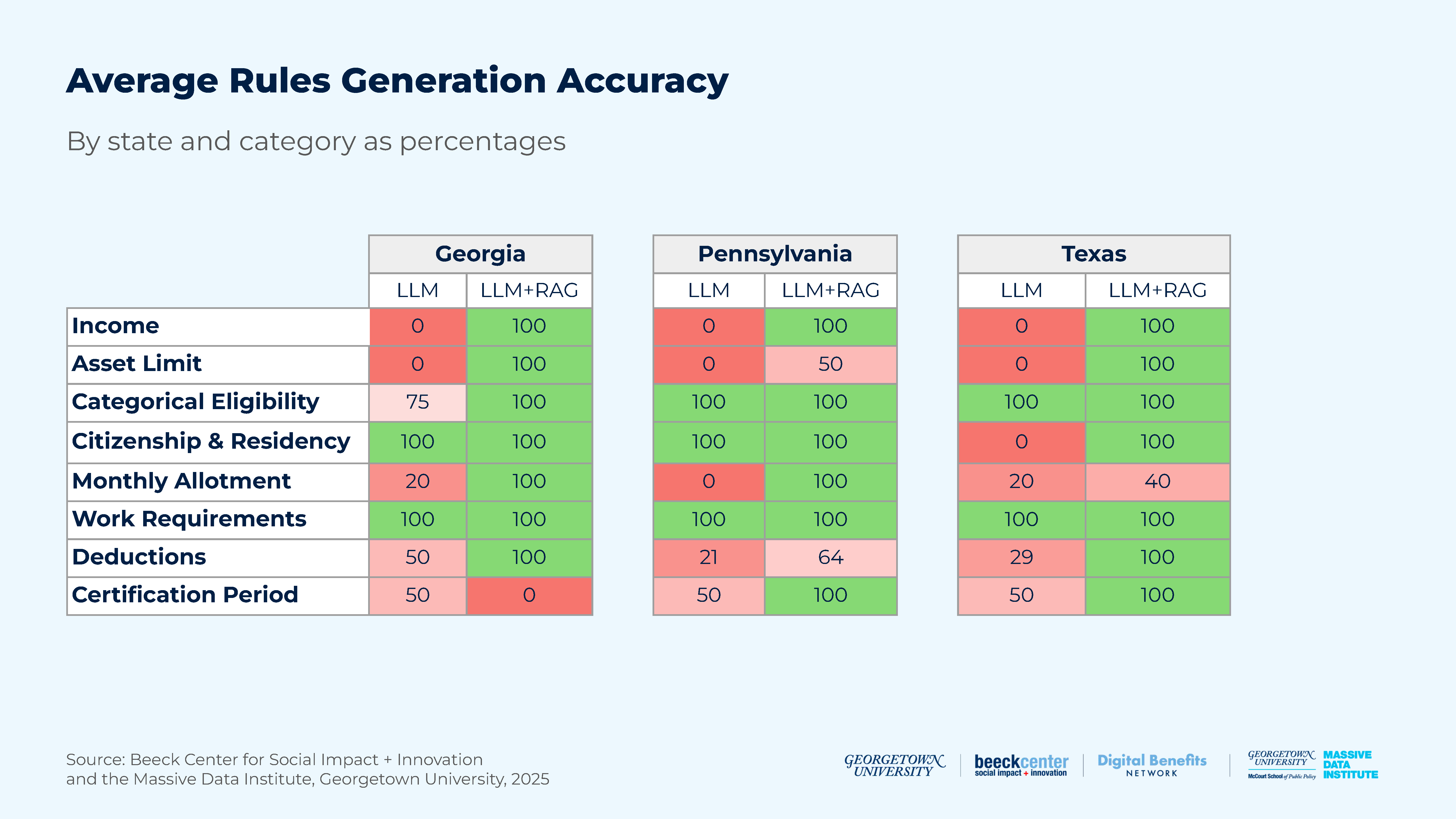
- Plain prompting yielded unreliable generation accuracy for state-specific rules. The plain prompting approach without the additional external knowledge (without RAG) demonstrated significant limitations with numerical rules like income and asset limits, achieving 0% accuracy in these categories across all states. Conversely, categories that were more likely to be consistent across states, such as citizenship and work requirements, were generated with 100% accuracy.
- RAG enhanced the alignment of generated rules with policy documents. The RAG approach effectively addressed the shortcomings of the plain prompting method by providing the additional context necessary to enhance both generation accuracy and timeliness.
- Structured templates are essential for rules extraction. The success of machine-readable rules generation is, to a large degree, dependent on the use of standardized templates. Public benefits agencies should collaborate to develop shared schemas that capture multiple levels of eligibility criteria. The absence of such templates results in significantly higher levels of inaccuracy and inconsistency in LLM output, further complicating interoperability with other components of an automated system.
- Rules generation can provide a structure for code generation. Given the success of rules generation for most contexts in this experiment, separating the rule generation from the code generation is a promising direction. While there is a need to begin with a manually-created template, once that is created, it can be part of a template library that can be used to generate the rules. The generated rules act as a structured skeleton of the code, providing the necessary logic for cleaner, more robust code generation. This multi-step, LLM-assisted implementation is a promising direction because policies in different states are inconsistently written. This variation means that translating certain highly variable policies directly to code may not be as promising a path for complicated policies as generating rules.
- Regular policy changes impact LLM output. To keep up with the recurring policy and legislative changes of public benefits programs, automated Rules as Code systems must remain up to date. This involves closely monitoring the LLM’s output to ensure it reflects the latest policy amendments. This might require scheduled model fine-tuning and updating the policy library used for document retrieval. Requiring the LLM to provide a reference for the generated rules may help with this as well.
- LLMs must handle dependencies across different benefits eligibility criteria. Benefits programs frequently involve interconnected requirements. For instance, a household’s gross income limits may vary depending on its composition (e.g., whether a member is elderly or disabled). If the LLM failed to account for such variations, it would lead to incorrect eligibility determination in automated systems. Therefore, careful handling of these dependencies is essential to prevent inaccuracies in LLM-powered automations. This could be addressed through detailed audits using test cases that feature intricate policy rules. A complementary approach would be to consider incorporating knowledge graphs into the RAG input, either independently or in combination with a traditional vector database.
- See the full experiment for details on the template driven plain prompting and RAG methodologies.
Experiment 4: Using LLMs to Generate Software Code
How effectively can an LLM generate software code to determine eligibility for public benefits programs?
Our primary objective was to understand the feasibility of using an LLM (GPT-4o) to automate code generation for key components of the benefits delivery process. By doing this, we began exploring how such automation could simplify access to benefits for eligible individuals, assist organizations in optimizing service workflows, and contribute to the development of more efficient and adaptable systems for managing benefits programs.
Figure 17: Experiment 4 Methodology
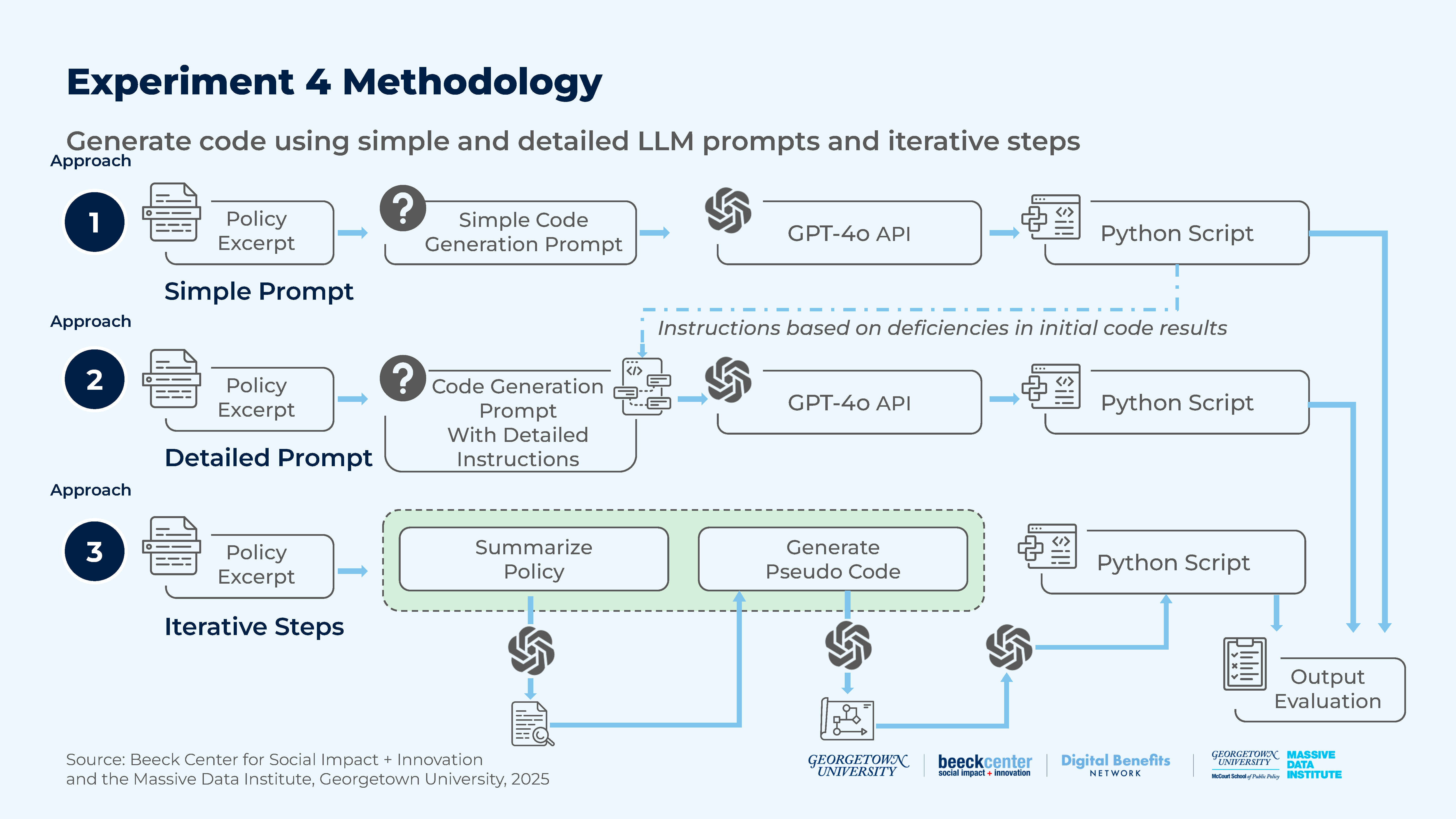
We developed three distinct experimental designs to assess how different inputs and prompting strategies impacted the quality and effectiveness of LLM-generated software code. Our goal was to determine the optimal input structure and level of guidance required by LLMs to generate accurate and functional code. Read more about our prompting strategies and external knowledge used.
- Design 1: Simple Prompt (Baseline): Created a policy excerpt and used a simple code generation prompt to generate code
- Design 2: Detailed Prompt (Guided Approach): Created a policy excerpt and developed a detailed set of instructions within the prompt that addressed the deficiencies of the Design 1 output to generate code
- Design 3: Iterative Prompts: Created a structured pipeline for code generation by inputting each step’s output as input for the next step so that the policy excerpt was used to prompt for a policy summary, which was then used to generate pseudo code (logic), which was then used to generate the final code.
Notable Results & Considerations
- At a high level, the detailed prompt design was the most successful. Our baseline experimental design generated unusable code, but did partially structure the logic effectively. The guided experimental design offered the strongest results for practical implementation when paired with human oversight. The prompts were refined and adapted to better align with policy rules, the underlying logic, and expected outputs. The iterative approach holds potential for complex and extended tasks; however, its utility depends on carefully mitigating errors that occur at each step of the pipeline through automated checks or expert review. Until more templates and standardized documents are developed, this approach is less viable than the guided approach.
Table 28: Performance of Designs Across Criteria
| Criteria | Design 1 Simple Prompt | Design 2 Detailed Prompt | Design 3 Iterative Prompts |
|---|---|---|---|
| Variable Identification | Partial | Good | Good |
| Input Handling | Poor | Partially good | Poor |
| Output Correctness | Incorrect | Partially correct | Incorrect |
| Decision Making | Poor | Partially good | Poor (mechanical) |
| Logical Consistency | Poor | Improved | Partially consistent |
| Rule Coverage | Partially covered | Improved | Partially covered |
| Code Execution | Runs (unstable) | Runs (Improved) | Doesn’t run |
- Summarized policy guidance for code generation reduces code errors. Our guided approach improved code quality significantly when compared to the baseline and also performed better than the iterative approach. Public benefits agencies should collaborate with each other to develop prompting frameworks that specify input format, variable naming conventions, and expected output structure to reduce ambiguities in LLM tasks, thereby improving the quality of the generated code.
- Modular design is particularly important in LLM workflows. Our findings show that LLMs struggle when they have to synthesize end-to-end logic for complex, multi-step tasks. Although their overall performance in the iterative approach was not markedly better than other methods, they showed a clear pattern of improved response quality when handling individual, compartmentalized tasks (e.g., summarizing policy). This suggests that public benefits agencies might potentially split complex workflows into smaller, reusable modules, which LLMs can tackle incrementally. At this stage, human developers are needed to both break down the workflow into reasonable chunks for LLMs and validate outputs from one step to the next.
- Accuracy and equity considerations must outweigh efficiency in high-stakes benefits systems. In code generation tasks—where outputs such as applicant eligibility status carry serious consequences and unresolved automation risks—we suggest treating LLMs as assistive tools to support human experts and developers, not as standalone solutions. Precision and fairness should be firm priorities in public benefits systems, making human oversight essential to ensure equitable outcomes. Efficiency gains from automation should not compromise these priorities.
Key Takeaways & Considerations for Public Benefits Use Cases
- Our experiments highlight that LLMs can support different parts of the Rules as Code pipeline, but a human in the loop and rich databases containing relevant, up-to-date policy excerpts are essential to facilitate the use of this technology.
- Using LLMs to distill benefits eligibility policies leads to mixed results. The returned information varies in its accuracy, timeliness, state-specificity, completeness, and relevance. The results are mixed across models and interfaces, including the web browser and APIs. While one model may perform better using a specific prompt type (e.g., income or individual eligibility) or category of scoring (e.g., accuracy or relevance), it may perform poorly with other prompts and categories, leading to mixed overall performance.
- Mixed LLM results have a direct impact on people seeking or receiving benefits, risking incorrect information when they ask generative AI models questions about programs like SNAP and Medicaid. When testing chatbots in Experiment 1, we found that Medicaid responses scored slightly higher overall than SNAP responses and that there were no major differences in the models we tested. Chatbots access information from the model’s training data, and it is often unclear if that information is from authoritative sources. This means that we should expect some answers from chatbots to be inaccurate and therefore, encourage people to not use chatbots to obtain information about benefits programs if a source for the information is not returned.
- It is possible to improve the performance of the benefits-related responses by pointing LLMs to authoritative sources like policy manuals. However, the current methods for communicating SNAP and Medicaid policy in fragmented PDFs and interactive websites make it hard for LLMs to use the information. State governments can make it easier for LLMs to use their policies by making them digitally accessible. At a minimum, this means a single PDF that allows text extraction; even better is a plain text or HTML document, or a webpage presenting the policy in full, including the effective date.
- When AI models provide incorrect information, they often do so in a confident tone, which can mislead those without subject expertise. This highlights the need for a standard way to quantify the uncertainty in AI responses, particularly for policy Rules as Code generation, where accuracy is essential.
- Asking LLMs to write policy code directly leads to poor code. However, a guided approach with attached policy excerpts and very detailed prompts yields better executable code, though it remains poorly-designed.
- Code generation can be improved by using an LLM with RAG to generate machine-readable policy rules. This is a viable alternative to manual rule curation. However, a manually-curated template is still necessary.
Potential for Future Experimentation
We encourage ongoing, open experimentation to test the application of LLMs in public benefits eligibility and the development of Rules as Code.
- Our methodologies can be repeated for other states, programs, policies, or LLMs. Given that our research captures LLMs’ performance at the time of our experiments, repeating these experiments as new versions are released can identify if and how performance improves with updates. Different prompting techniques, such as active prompting, may also improve LLM performance in Experiments 1 and 2. All experiments can also be applied to additional states, programs, and policies.
- Policy experts and software engineers can pair programs and evaluate. We conducted these experiments with general policy knowledge and computer science students. We’ve been following Nava Labs’ project to work closely with benefits navigators and their design and engineering teams to develop new tools for benefits access and enrollment. Working with policy experts would be fruitful for capturing policy logic templates more effectively.
- Explore creating a LLM for a specific program or policy. Creating specific LLMs fine-tuned for a specific program—such as SNAP—and continually updated as policies change with a RAG is an important direction, allowing states to have a stronger starting point in this space. Additionally, a program-specific model could have increased capabilities to understand differences between federal and state policy.
- Consider different programming languages for outputs. Experiment 4 could be explored using different programming languages to see if some LLMs are more or less successful at generating code.
- Compare results against existing systems. Administrators of eligibility and enrollment systems could compare results against the code and information provided by those systems. Additionally, many existing systems also have test cases that could be used to evaluate LLM outputs.
- Explore extracting code from legacy systems. Many eligibility and enrollment systems are written in legacy code languages. Administrators could explore using LLMs to convert the legacy code into an updated language using a guided template.
- Compare code writing efforts to policy analysis efforts. It is unclear how much effort using LLMs can save when developing Rules as Code infrastructures for different programs. An analysis of this may highlight a shift from programmer time to policy analyst time.
How We’ve Been Advancing Rules as Code
The Digital Benefits Network (DBN) and Massive Data Institute (MDI) teams are among the first to extensively research how to apply a Rules as Code framework to the U.S. public benefits system. We draw on international research and examples, and have identified numerous U.S.-based projects that could inform a national strategy, along with a shared syntax and data standard.
The DBN hosts the Rules as Code Community of Practice—a shared space for people working on public benefits eligibility and enrollment systems, particularly people tackling how policy becomes software code.
Get in Touch
We’re eager to hear from you. This work, like any public-facing project, improves as more stakeholders offer their input. We welcome your thoughts, questions, or potential collaboration ideas. Email us at rulesascode@georgetown.edu.
This publication is a summary of the AI-Powered Rules as Code: Experiments with Public Benefits Policy report.


