Exploring Rules Communication: Moving Beyond Static Documents to Standardized Code for U.S. Public Benefits Programs
This brief analyzes the current state of federal and state government communication around benefits eligibility rules and policy and how these documents are being tracked and adapted into code by external organizations. This work includes comparisons between coded examples of policy and potential options for standardizing code based on established and emerging data standards, tools, and frameworks.

The benefits programs that comprise the United States social safety net are governed by a complex array of federal, state, tribal, and local entities. Currently, governments enact and promote a tangle of intersecting laws, regulations, and policies related to these programs, which are communicated in lengthy and complex text documents distributed on disparate websites.
The absence of standardization and transparency in public benefits governance fundamentally limits the ability of benefits administrators and delivery organizations. It makes it difficult to ensure residents can access the benefits for which they are eligible. One foundational approach to reducing the gap between policy and service delivery in digital systems in the United States is adopting rules as code for the safety net. (The Organization for Economic Co-operation and Development (OECD) Observatory for Public Sector Innovation defines rules as code as “an official version of rules (e.g., laws and regulations) in a machine-consumable form, which allows rules to be understood and actioned by computer systems in a consistent way.”) Doing so would enable more straightforward policy integration into delivery systems that are both standardized and transparent.
To help eligible individuals navigate the complexities of benefits delivery, a vibrant community of organizations have created online eligibility screening tools, benefits applications, policy analysis tools, and open source resources across numerous public benefits programs. These organizations play a crucial role in increasing access to benefits for eligible individuals, and serve as tangible examples of how open, standardized code can translate policy into system rules.
In this brief, we analyze the current state of federal and state government communication around benefits eligibility rules and policy and how these documents are being tracked and adapted into code by external organizations. This work includes comparisons between coded examples of policy and potential options for standardizing code based on established and emerging data standards, tools, and frameworks.
We hope that this analysis sparks dialogue and progress in advancing a standardized, open rules as code approach for the U.S. safety net. When this is achieved, rules will be communicated using a common, expandable syntax, they will be easy to find and incorporate into digital systems, and will be kept up to date to reflect the latest policy changes and new types of policies and benefits as they arise.
The analysis in this brief builds upon:
- The first report looking at rules as code applied to the U.S. public benefit system, Benefit Eligibility Rules as Code: Reducing the Gap Between Policy and Service Delivery for the Safety Net, published in February, 2022 by the Digital Benefits Network at the Beeck Center for Social Impact + Innovation.
- Rules as Code Demo Day hosted by the Digital Benefits Network in June, 2022 where more than 200 attendees joined for eight demonstrations of rules as code followed by discussion sessions.
- Two short form reports, Applying Rules as Code to the Social Safety Net and Envisioning a Federal Rules as Code Approach to Public Benefits Eligibility, and rules as code case studies and resources, which can be found on the Digital Government Hub’s Digitizing Policy page.
Current State: Static Documents from Federal and State Government
While the federal government sets baseline policy and rules, flexibility in state implementation around benefits makes an already complex process even more difficult and results in state-by-state variations in thresholds for eligibility.
As part of our research, we explored how federal and state agencies communicate eligibility rules and how organizations developing eligibility screening, benefits application, and policy analysis tools keep up-to-date with rule updates.
Federal Rules Communication
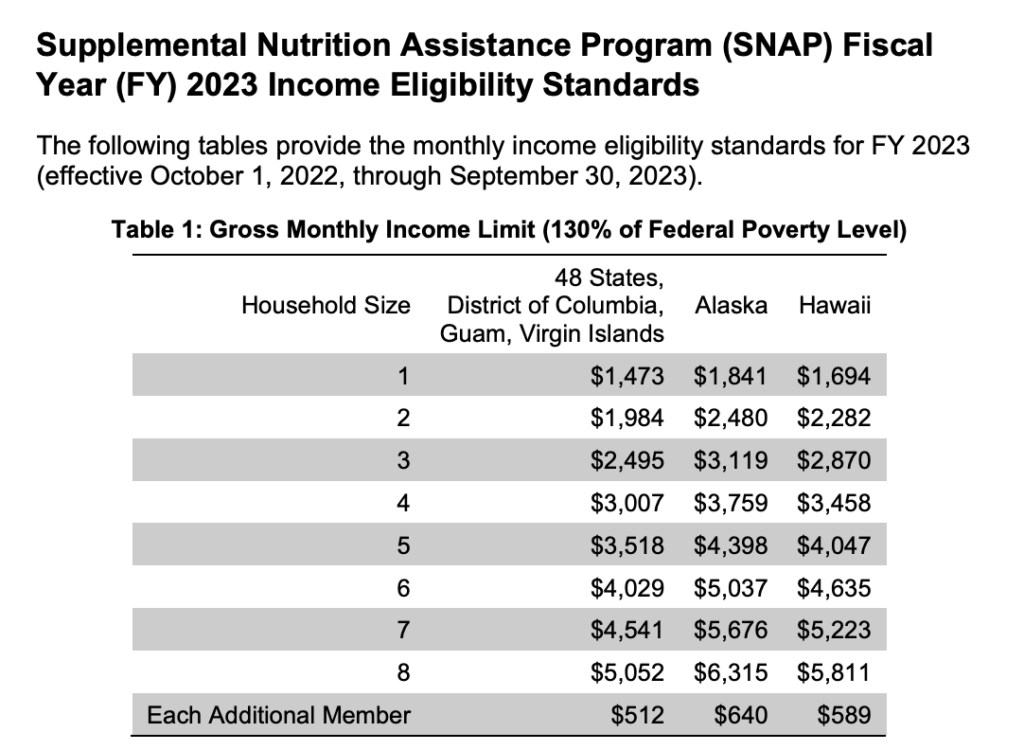
Tracking eligibility rule changes at the federal level is often straightforward given the limited number of rule updates, consistency in rule update schedule, and centralized rule communication source. For example, the cost of living adjustments for Supplemental Nutrition Assistance Program (SNAP) are updated annually on October 1 and communicated via the U.S. Department of Agriculture’s (USDA) Food and Nutrition Service (FNS) website via a policy memo. Most delivery organizations have recurring reminders around these annual changes so they can visit the website and receive these updated figures. There is a problem with this process, though. The USDA’s updated information is shared via PDF documents, which are not in a computer-readable format such as a text file, HTML table, or a code option would be.


State and Territory Rules Communication
There is also a wide disparity in the ways state and territories create and disseminate information around tracking eligibility rule updates. For delivery organizations aiming to deploy national eligibility screening and policy analysis tools, the inconsistencies in rule communication across states and territories present additional challenges and create duplicated efforts.
During our interviews, delivery organizations recounted difficulties finding policy manuals for certain states, extracting relevant eligibility rules, keeping up-to-date with eligibility rule changes resulting from inconsistent updating schedules, and in some cases, incomplete eligibility rule information for certain states. These types of data collection challenges hamper the accuracy of eligibility pre-screening, creating challenges for delivery organizations that want to expand the scope of their services. The challenges affect organizations looking to include more benefits programs, limit cross-benefit eligibility screening and enrollment, and increase the administrative burden on nascent organizations attempting to develop new benefits resources.
Additionally, inconsistencies in digital rule communication render the attempts to automate the rule tracking process nearly impossible. One could imagine automated tools monitoring certain website pages for rule updates catered to specific states and programs. However, the value of such a tool does not outweigh the burden of creation given that rule updates are not always communicated on the same website pages and digital access to rule communication as a whole varies across states.
For individual states and territories, these disparate roadblocks translate into burdens. They must manually review and update policy documents. Given that there is little consistency around how rules are communicated, and no state or territory has open coded rules, agencies and organizations are left relying on the aforementioned PDF documents and web pages.
To illustrate these complexities this report looks closely at communication of SNAP eligibility rules. It should also be noted that SNAP is one of the primary benefits programs in the US. Therefore, the following information on eligibility rules — specifically open-source resources dedicated to the program — is comparatively more extensive than smaller scale benefits programs.
SNAP allows states and territories to have flexibility when determining eligibility thresholds. Variations to the general program rules depend on the policies each state or territory adopts. One way to improve rule tracking is by categorizing states and territories by eligibility formula and degree of variation to the general program rules which are largely dependent on federally communicated rules.
Given varying eligibility thresholds, FNS previously published a State Options Report, based on a survey of states to communicate which rule options are in effect. However, it was last published in 2018, reflecting options and information that were in effect as of October 1, 2017.
The State Options Report centralized rule communication and provided delivery organizations a reliable source to track rule variations. In the absence of such reports, each delivery organization maintains its own database with information on state and territory eligibility rules. As a result, delivery organizations duplicate research efforts and employ different strategies to track state and territory eligibility variations. Many delivery organizations report inconsistent online access to rule handbooks and differences in format and content of rule communication across states and territories. Indeed, no delivery organization claims to offer a one hundred percent complete and accurate database of state and territory eligibility rules.
Case Study: Nonprofit mRelief tracks state and territory eligibility rule updates for SNAP
mRelief—a nonprofit software product organization which helps people in all 53 states and territories participating in SNAP find out if they are eligible and apply for SNAP—categorizes states and territories into three groups:
- States that do not confer to Broad-Based Categorical Eligibility (BBCE) and instead apply the regular program rules requiring prospective applicants to meet a certain net income threshold in order to be deemed eligible. Only nine states do not confer BBCE: AK, AR, KS, MS, MO, SD, TN, UT, WY.
- States with BBCE.
- States with BBCE and further adjustments to the net income formula.
Tracking rule updates within each of these consolidated buckets is conducted manually via state and territory rule handbooks (if they exist) and other online resources.
Several public resources exist to aid navigation of state and territory eligibility rules for SNAP. For example, FNS publishes Standard Utility Allowances (SUAs) as an Excel spreadsheet as well as the broad-based categorical eligibility (BBCE) rules as a PDF. Benefit navigator organizations, such as Hunger Solutions New York, also create guides that help piece together eligibility. However, each of these resources must still be supplemented by individual research efforts given they often contain incomplete content and create issues with reliability changes that states may make.
FNS has compiled a comprehensive state-by-state interactive database, directing prospective applicants to the state websites for SNAP. The information in this directory is catered to prospective applicants and, therefore, does not provide links to policy manuals and other open source resources outlining state level statistics.
A more practitioner-oriented database has been compiled by the Center on Budget and Policy Priorities (CBPP). In creating this directory, CBPP provides additional insight into state-by-state rule communication. CBPP confirms that there exists “significant variation among states’ SNAP websites and their online services.” One prominent variation across SNAP state websites is access to services, including program applications, the availability of benefit calculators, pre-screening tools, policy manuals, memorandums describing rule updates, and links to social media accounts.
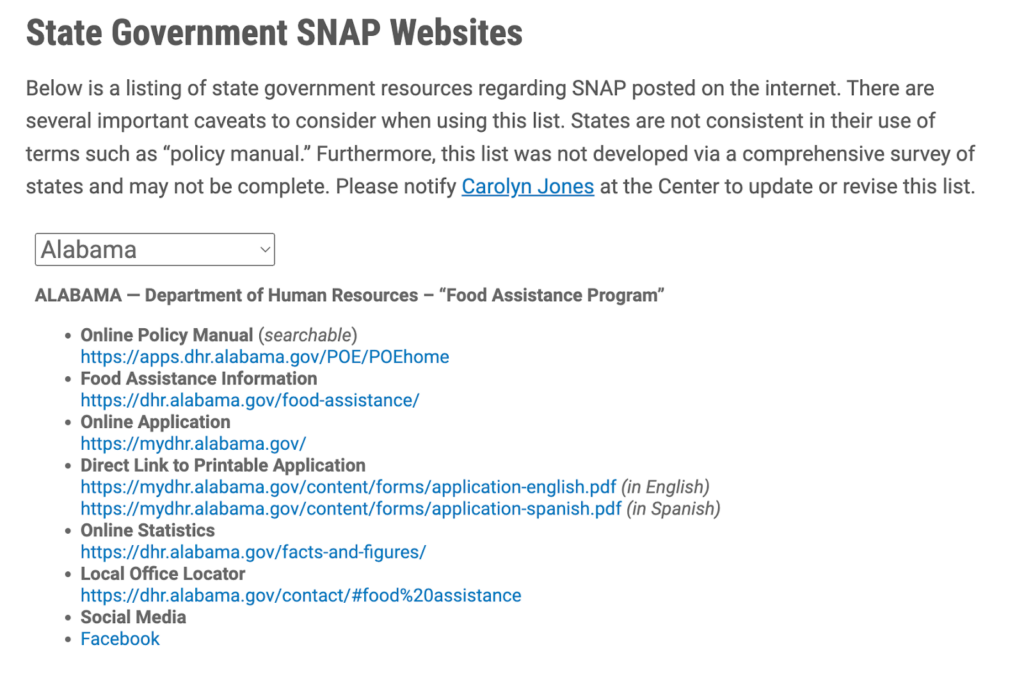

In assessing state and territory rule communication, it is also important to note the quality of policy manual access and deployment across states given the crucial role these manuals play in communicating rule updates to public organizations.
Ben Molin, the co-founder of SNAP Screener, an unofficial calculator that helps users to find out whether they are eligible for food stamps and estimate the amount of benefits they can receive, provides insight into his experience using state SNAP policy manuals in an interview with our team:
“The most important resources a state can provide about SNAP are the accurate (BBCE) gross income and asset tests for their state. So my two criteria for evaluation of a state’s resources would be: (1) How easy is it to find the BBCE income limits? And (2) How easy it is to find the utility allowances. If they have utility allowances information easily available, it is a great indicator about the rest of their resources.”
SNAP Screener maintains a publicly-accessible table of eligibility parameters for SNAP, which brings together information from federal and state resources.
Molin identifies Pennsylvania and Alaska as two states that have excelled in communicating eligibility rules in their policy manuals. On further examination, we highlight several important features of policy manual communication:
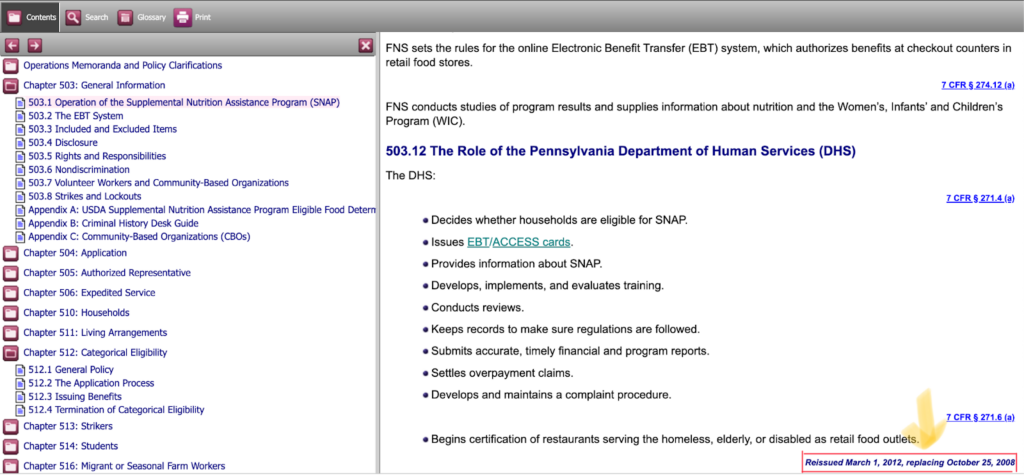
- All policy rules are presented in a single interface. The interface is accessible and includes links to all pages via an easy-to-use navigation bar that can toggle between different policy rules. (See both Pa. and Alaska, Figure 1).
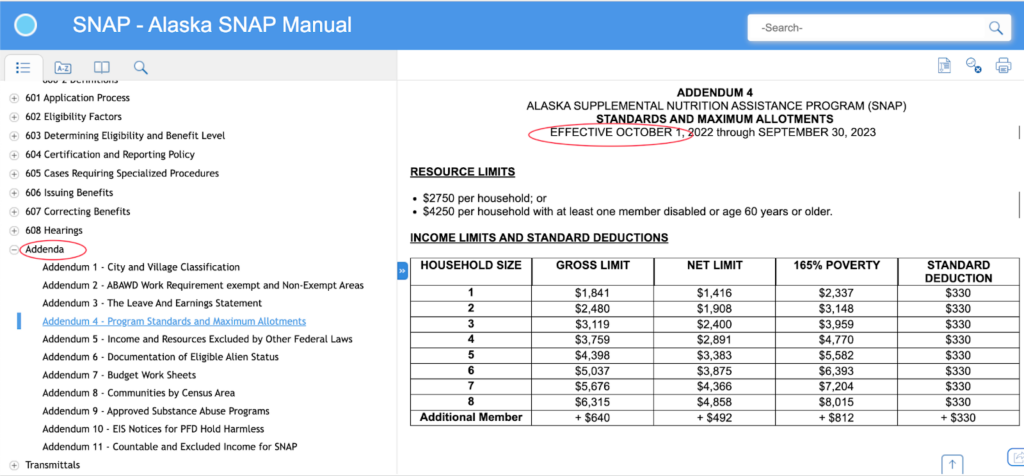
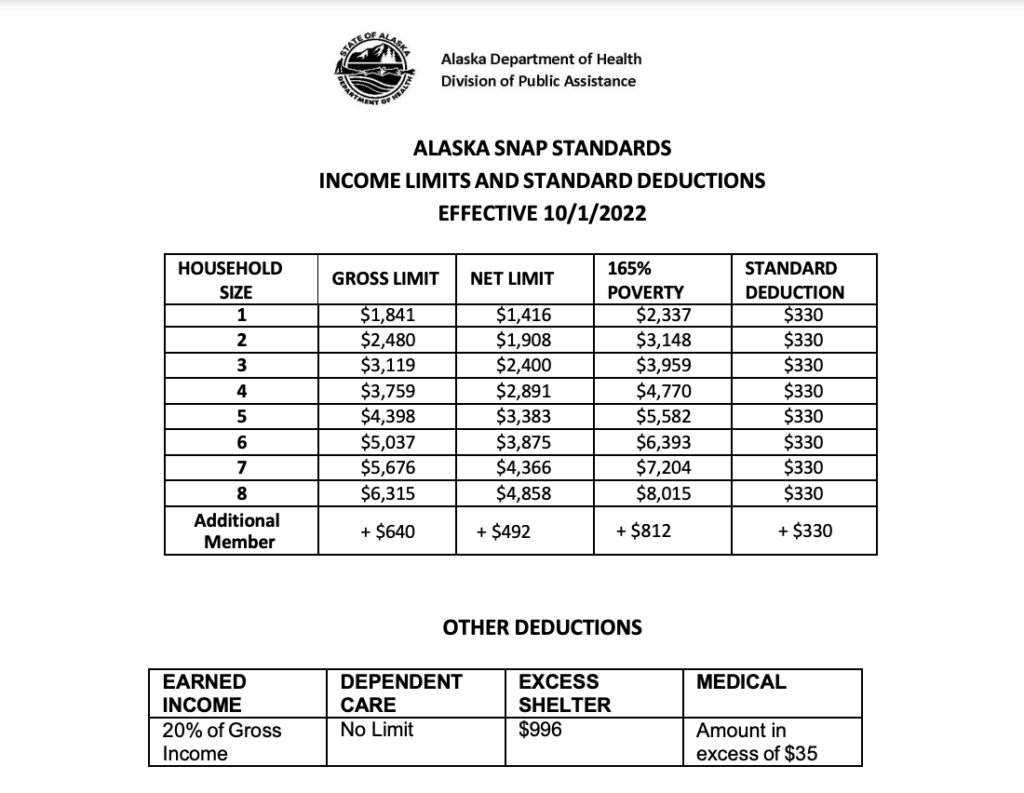
- There are separate pages for figures presented in easy-to-read tables with clear effective dates (see Pa. and Alaska, Figure 2).
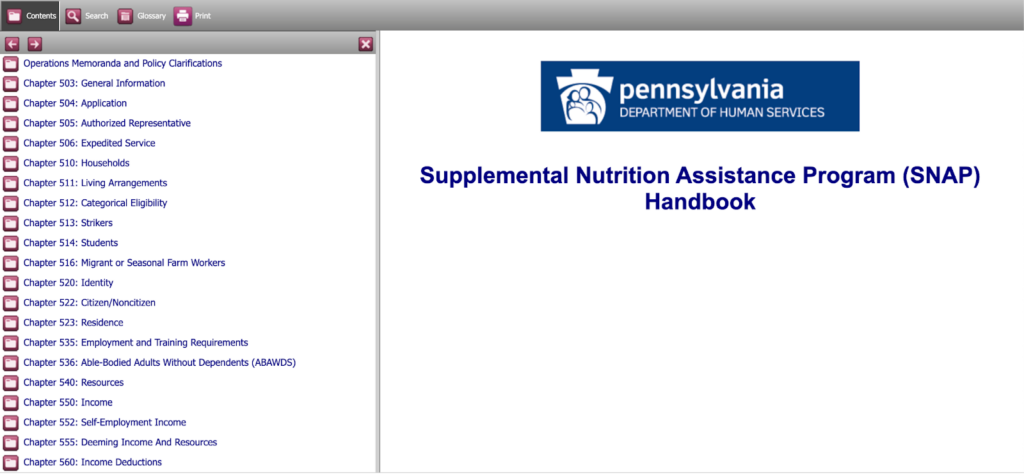
Pennsylvania SNAP Policy Manual
The following screenshots highlight several favorable, user-friendly features of Pennsylvania’s SNAP policy manual.

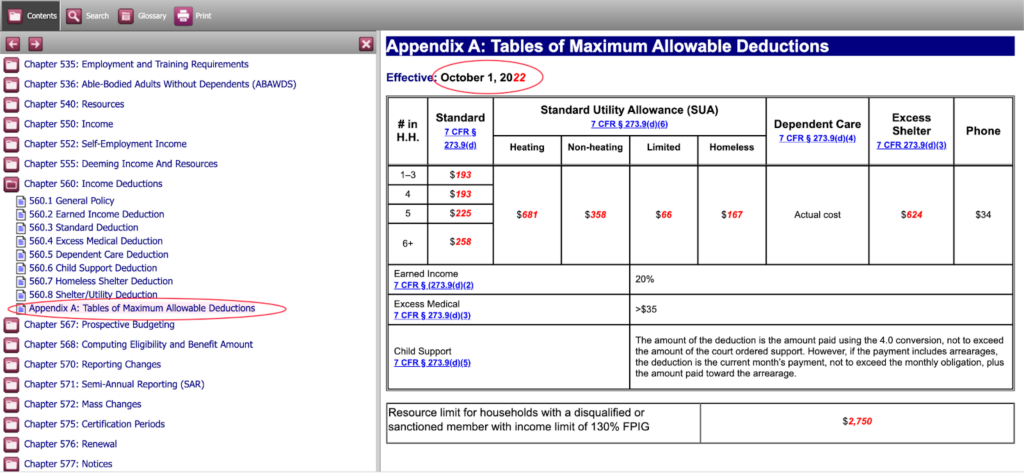
Alaska SNAP Policy Manual and Short Summary of Annual Adjustments
The following screenshots highlight several favorable features of Alaska’s SNAP policy manual.
However, state and territory rule communication is not often as easily navigable and complete as the Pennsylvania and Alaska policy manuals. Below are some examples at the other side of the spectrum with regard to the quality of online rule communication.
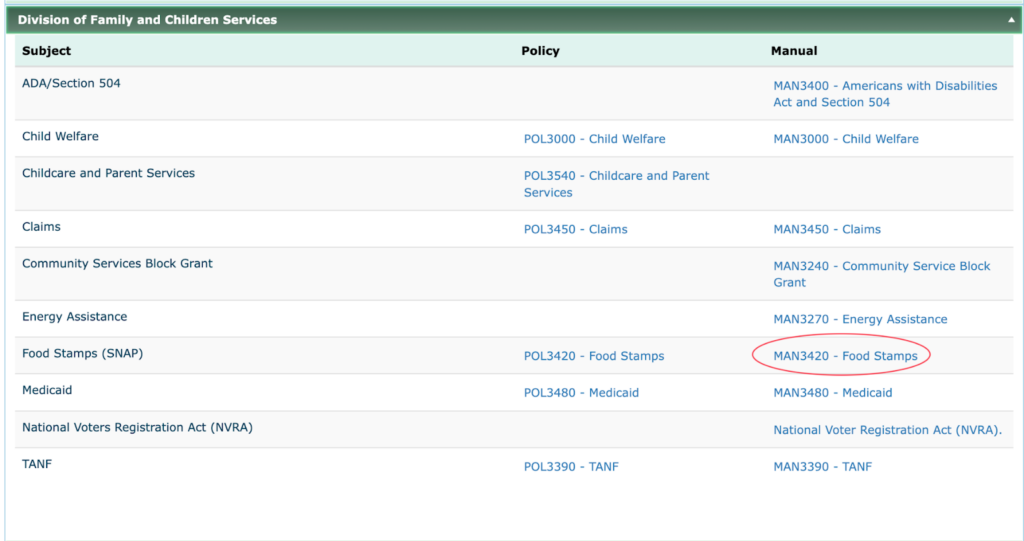
Georgia SNAP Policy Manual
The following screenshots highlight several examples of poor rule communication.
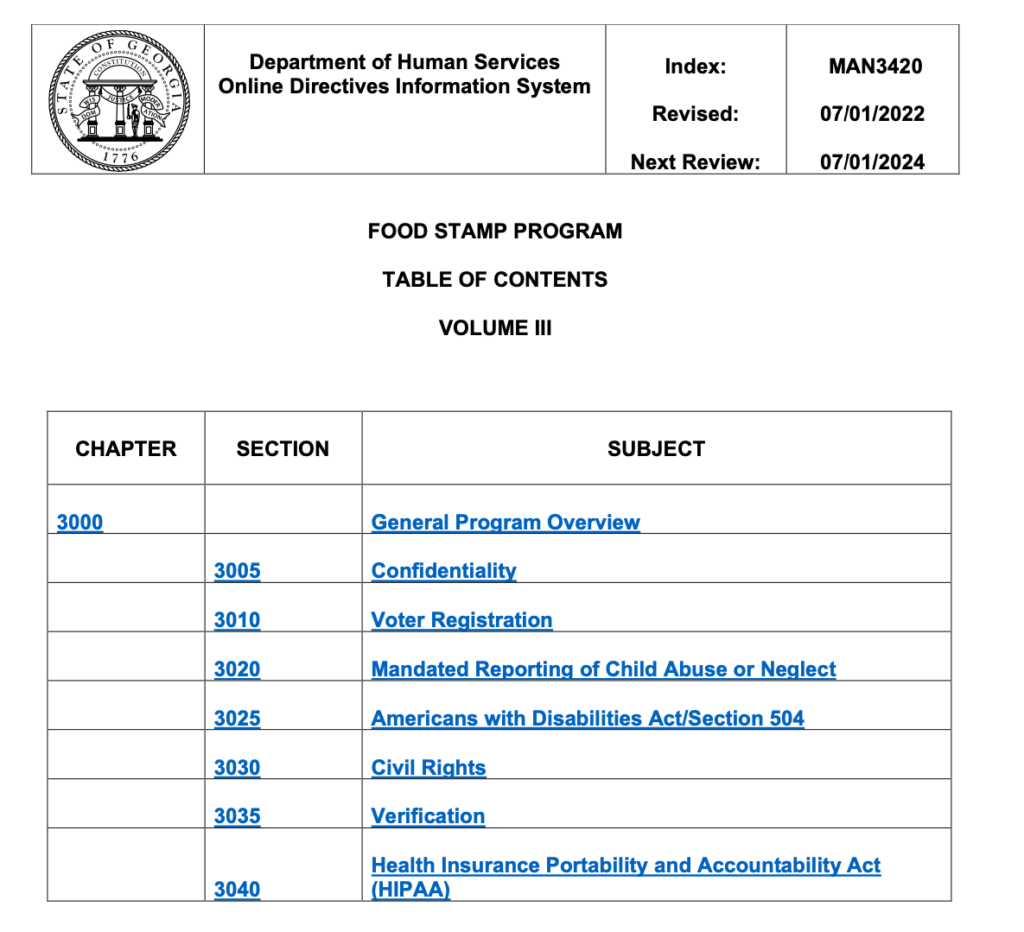
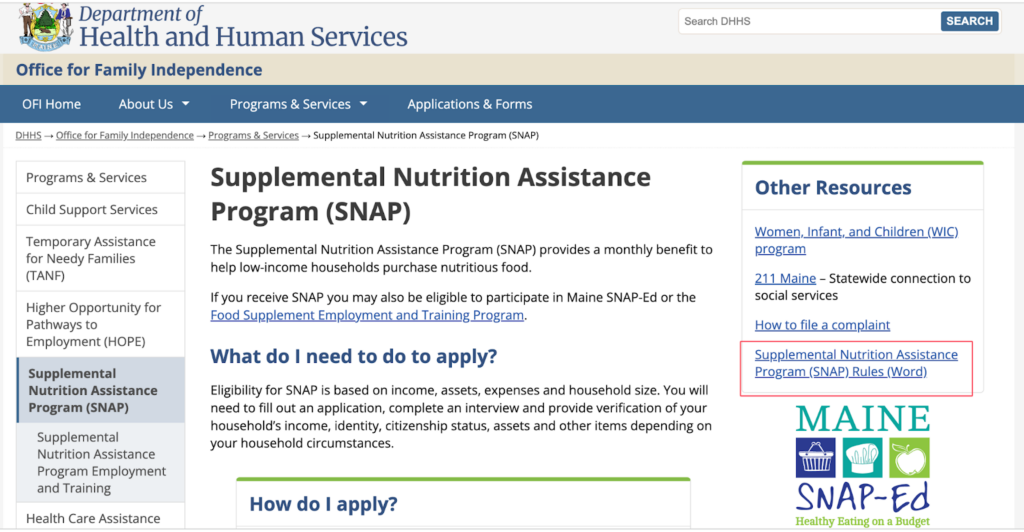
Maine SNAP Policy Manual
The following screenshots highlight several examples of poor rule communication within Maine’s documentation.

There is an opportunity to improve the usability and standardization of policy manuals. By taking a rules as code approach, for example, government entities can issue logic flows and computer-consumable code versions of laws, regulation, and policy alongside their legal text counterpart, via open source rules code and data feeds. This data can then be integrated into any organization’s digital system.
Evolution: Projects Translating Policy into Open Code
To explore how different organizations handle translating policy documentation and eligibility criteria into code, we conducted a case study of four organizations that have publicly shared their code and documentation. These organizations include the Federal Reserve Bank of Atlanta Policy Rules Database, ACCESS NYC, 18F Eligibility API Prototype, and PolicyEngine. We begin by comparing them using the following criteria: documentation completeness, application programming language, framework used for incorporating policy rules, code base availability (i.e. Is it open source?), code base usability (i.e. Is it written in a well-known language?), and rules adaptability that includes the ability to add policy updates and new rules easily. We then focus on overall design considerations that are important for increasing interoperability and standardization and connect these design decisions to each organization’s tools. The following table describes these organization tools in terms of these criteria.
Comparison of Different Rules as Code Software
Do you know of another project that would be useful to include? Send us a note with your suggestion.
Documentation is vital to the success of any rules as code approaches. We define three categories of documentation: limited, moderate and extensive. Limited documentation explains how to run the code and includes some general background information. Moderate documentation explains the variables and provides some basic information about how a decision about a specific benefit is being made. Both limited and moderate documentation will also typically lack some organization. Extensive documentation shows how the software can be used and explains the different design decisions. It maps actions that a typical user would conduct to definitions, variables, and code logic snippets. Calculations are also clearly explained. Together, the documentation makes it easy for developers and analysts to see what needs updating when policies and rules change. We find that in general, documentation tends to be moderate or extensive. This is important since many developers who want to use these code bases may not be well versed in SNAP regulations or in a rules as code framing.
We see that each of our four case study examples uses a different programming language and different framework. For example, for its Policy Rules Database, the Federal Reserve Bank of Atlanta has built a custom rules engine. It is not built using a rules as code framework, such as an open source template for implementing rules as code that can be expanded on to fit a specific use case, (e.g.: 18F or OpenFisca), or any tool specifically used for encoding rules (such as Drools).
Instead, it uses its own structure, implementing the logic for each program in a function using information from data files that contain the eligibility criteria. The tool was built using the R programming language. While R is a general purpose statistical programming language, it is not as ubiquitous as Java, Python, or JavaScript. The program data files do persist over time, though and show the state eligibility criteria for each program annually for different household sizes. This is a beneficial component since it maintains a historical record of policy changes and gives users a way to understand how changes impact benefits usage.
We do have one concern with the Policy Rules Database code. There are some specific rules or calculations that are hard-coded in the program. If those rules change over time, not only do the data files need to be updated, but so does the code itself. This means that the code base is probably less flexible than one with a higher level of abstraction that was designed with more modularity in mind. In general, this tight coupling between the rules and the code makes it difficult to identify what information should be updated and where in the code it needs to be updated in response to a change. The Atlanta Fed is in the process of updating their tooling with a different language with the goal of addressing some of these concerns.
ACCESS NYC decouples the policy logic from the application code by using the Drools framework. Drools is a rules engine that was developed using Java, a general purpose programming language. This rules engine allows for rules to be written at a higher abstraction level than programming them directly in Java or a different general purpose programming language. The Drools engine does allow for the rules logic and the data to be separated, new rules can be added without updating existing rules, and the rules themselves are readable. While this solution has a number of strengths, including codebase standardization and straightforward creation of new rules, there are some drawbacks as well. First, there is a steep learning curve required to use the Drools framework. Second, the format of the rules is specific to the Drools’ rules engine and is not easily adjustable to other formats. This limits its interoperability. So even though the framework is built using Postgres, an open-source relational database, and the Java programming language, it is a highly restrictive language with limited exporting capabilities, making it difficult to integrate easily with a different technology stack.
The web-based ACCESS NYC eligibility screener serves as an example of the type of tool that can be built using the business logic stored in the rules database. The organization’s team also created an Application Programming Interface (API) that calls the rules engine in order to determine potential eligibility for various programs outside of the ACCESS NYC front end screener. This can be used for batch screening households for benefits or creating new benefits screening tools for a specific use case as it enables running household data against eligibility rules for city, state, and federal programs.
Starting in 2017 through 2020, a team at 18F, part of the General Services Administration, prototyped how the federal government could communicate benefit eligibility rules as computer code for integration into state systems. Under their Eligibility APIs Initiative, the team built a prototype API and calculator for the federal rules for SNAP. Through this development, they created the open source 18F prototype framework, which has now been reused by other tools like SNAPScreener. SNAPScreener extends the data model to all U.S. states and territories. In the framework, the program data is stored in JavaScript format. The correct values for information such as state deductions amounts, income limit factors, and broad based categorical eligibility determination are retrieved for the state and year from the JavaScript file, and applied to common functions that can be used for any state to retrieve an individual’s estimated SNAP benefit. We view this solution as one that mixes the benefits and functionality of the Federal Reserve Bank of Atlanta and ACCESS NYC. The rules data are stored in a separate file that can be updated without updating the code associated with the user application itself. Simple text files allow for the decoupling of the data from the application interface code logic. Traditionally, these simple files can lead to complexities when formats change since all the data in the file will need to be rewritten in the new data format. However, this framework uses the JSON format for the data stored in these text files. That format is a well established lightweight format that is as interoperable as data stored in a traditional relational database. Also, the JSON files can be shared publicly, making it more accessible than many government databases. The disadvantage of formats like JSON and XML compared to SQL (the language used to access data in traditional relational databases like MySQL, Postgres, and SQLite) is that code needs to be written to manage, access, and manipulate the JSON files. With SQL, the data management can be taken care of by the database management system.
Finally, PolicyEngine also uses tools specifically designed for handling rules logic. It is built on the international open source OpenFisca framework. The tool uses YAML files to store information about the benefit programs, while its backend is implemented in Python. Its client-facing website was built using JavaScript. Similar to the Policy Rules Database, it computes an applicant’s income eligibility threshold using a multiplier against the federal poverty line threshold. This multiplier, like the threshold itself, is stored in YAML. The language the tool uses is generally used for working with data and, similar to JSON, is serializable. Some developers prefer using YAML because it allows for commenting and supports more complex data types than JSON.
Because PolicyEngine supports a wide range of programs and holds information about tax policy as well as benefits, it contains significantly more data than the other tools we analyzed. In general, YAML has the same strengths and limitations as JSON in terms of interoperability, scalability, and comparisons to traditional relational databases. We note that all of the files generated using these different markup languages can be readily moved to databases as the number of rules and files grows. During the development period, using files that allow for flexible schema adjustment may be more efficient and enable more projects to be developed concurrently.
Overall Design Considerations
We can see from the high level comparison that each team had different constraints when designing their tools. The most noticeable difference was the variation in the programming languages used. While the languages each of the organizations used are mainstream, general purpose, or data languages, they are different in terms of the use cases for which they are best suited. The rules developed are also not language agnostic. As previously mentioned, the examples we examined have varying levels of application and data coupling. Those with higher levels of abstraction may be more readily portable to different contexts, such as other states or programs. The tools also differ in terms of when conditions are applied. For example for SNAP, the gross income test is not applied to households with elderly or disabled members. PolicyEngine includes this check as part of its calculation, while the 18F prototype keeps the test as a part of the gross income computation threshold and only calls the test when applicants have specific household information. While this may seem like a trivial distinction since both approaches lead to the same result, this policy rule was translated into different code logic. If there are no basic guidelines as to which logic structure to use, variability will occur and portability will decrease.
These differences highlight a number of design considerations that are important moving forward. First, a broad design consideration is whether or not the software should be developed for a specific benefits use case. In this study, three of the four examples were designed specifically for SNAP. This means that it may require more effort to adapt to other benefits programs. Second, there are rules that are fairly consistent across states and rules that are very specific for certain jurisdictions. It is important to design tools that compute rules that are compliant with policies in the jurisdiction of interest. But it may also be beneficial to standardize how policy and rules logic map to rules code, irrespective of the state the rules are being developed for. This would help make the rules code (and rules engine) reusable for different benefits programs. Finally, if we want plug and play rules as code, we need to modularize and separate out different components so that standards can be established for each component. As an example, designers may want to think about what should take precedence in terms of determining eligibility: categorical eligibility or standard eligibility thresholds? Consistency across these types of design decisions are important for increasing modularity and reusable components.
To make some of these design decisions more concrete, we suggest considering the following categories of decisions: (1) rules parameter data format, (2) the mapping between policy, rules logic, and rules data, (3) rules engines, and (4) developer interfaces. The rules parameter data format consists of the naming and data value conventions that are being used to determine benefit eligibility, e.g. income level or poverty rate. The mapping between policy, rules logic and rules data is the pseudocode that connects the policy and data fields to conditional logic. For example, add A + B + C to produce TOTAL and check that TOTAL < D. Rules engines generate and interpret the rules to ensure compliance given the set of data fields and rule logic. Developer interfaces are what the application developer uses to build interfaces that users can interact with when determining their benefit eligibility.
Ultimately, each of these design decisions will influence how uniform the rules are across contexts and how easily different states can take advantage of the work done by the rules as code community. When looking at these components in the context of the specified goals, all of these design decisions are important for portability and standardization. This includes standard file formats, data standards, rule languages and specification standards, etc. The usability of the rules as code framework hinges on a clear and easy to understand mapping between policy, rules logic, and rules data and an implementation of them within rules engines that is simple to use and straightforward to add new policies to. If the rules and data are very tightly coupled, the code will not be usable outside of its original context without custom code for adapting the rules code to the new context.
In the case of our examples for SNAP, the SNAP Screener prototype does use a portable data format (JSON), but the mapping between the policy, rules logic and rules data are custom implementations that would need re-implementing for other use cases. These rules were not generated using a rules engine and the developer interfaces are also not generic. One strength is that the code-base is straightforward and could be manually adjusted for different use cases. If we consider ACCESS NYC, it is the best example of decoupling data and application logic. It accomplishes this by using a rules engine. The Drools engine is used to standardize the generation of rules, ensuring both a consistent data format and a strong mapping between the policy, rules logic and rules data. While the generation of the rules can typically not be accessed by the public, the API gives access to the outcome and these outcomes can be integrated into different applications that users can access. As a general principle, the more independent each of our four design decisions are, the more versatile the code-base will be and the easier it will be for multiple disparate states to use different modules.
Recommendations
As we work to advance the use of rules as code, each of the different case study examples we examined can be used to evaluate the strengths and weaknesses of software design decisions. While this cursory look has uncovered advantages and disadvantages, there are many aspects of information we are still missing. For example, what resources were available for each of the different initiatives? What resources does each entity need in order to successfully maintain and update software when program changes occur? How stable are the languages used to code each application and do any of the organizations have concerns about software or stability moving forward?
Given these questions, our community needs to come to an agreement on a basic set of standards in order to support states considering using rules as code. We also need to think about ensuring interoperability between rules engines in order to reduce the burden of development for different states. Finally, a more comprehensive auditing of code, even those created by states that have more proprietary codebases, should be conducted. Doing so will ensure that states will implement these code bases and rules correctly and that every rules as code implementation is designed to be extensible and can be easily adapted to constraints that exist in different states.
Future Course: Standardized Rules as Code
In addition to open code bases, there are other frameworks available that could inform the standardization of communicating rules as code for U.S. public benefits programs. We believe it is important to evaluate any framework or standard that is already available, testing to see if they could be further adopted and developed. This would help states save money and time that would be spent creating something new.
Existing Frameworks and Tools
The embedded Airtable below communicates the differences between the frameworks and tools we have identified as potential alternatives. Each entry is tagged with different categories that identify the type of framework or tool it is.
Do you know of another framework or tool that would be useful to include? Send us a note with your suggestion.
Definitions
| Business Process Visualizers | Software solutions that model processes graphically. |
| Rules Engines | Software that models specific rules. |
| Automated Decision Making | Frameworks and tools that utilize artificial intelligence (AI), machine learning (ML), and/or other automatic processes to make decisions. |
| Data Format Standards | Sets of rules that apply to select pieces of information. |
| Standards Bodies | Entities that manage an information standard. |
| Technical Language/ Specification | Software framework for standardizing the translation of policy and legislation into rules and code. |
Comparing Coded Rules Across Frameworks
In this section, we examine two SNAP rules, comparing them using the lens of our case study subjects. We evaluate them across the available open code tools and model them using the different frameworks. These two selected rules from the SNAP Policy Manual enable us to explore how different organizations handle both a standard eligibility threshold rule and a categorical eligibility rule.
Do you have code you would like to share? Send us a note with your suggestion.
| NY SNAP Policy Manual Rule | Translation into Eligibility Question | ||
|---|---|---|---|
| The monthly gross income eligibility standard is 130% of the annual federal income poverty level divided by 12. Accessed via the following links in November, 2022: https://otda.ny.gov/programs/snap/SNAPSB.pdf https://otda.ny.gov/policy/gis/2021/21DC064.pdf https://otda.ny.gov/programs/publications/5104.pdf | ACCESS NYC: Do you have an income? This includes money from jobs, alimony, investments, or gifts. | 18F: Monthly household income before taxes from jobs or self-employment | PolicyEngine: What is your employment income? Wages and salaries, including tips and commissions |
ACCESS NYC
Policy Rules Database
18F Prototype API
Policy Engine
Catala
Blawx (v1.3.41-alpha)
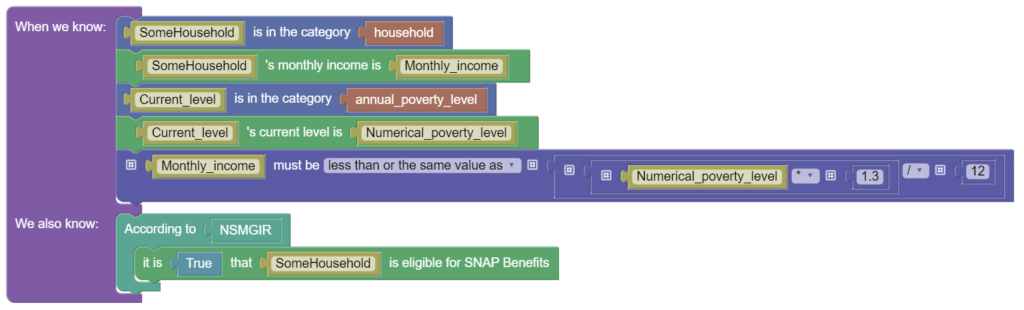
| NY SNAP Policy Manual Rule | Translation into Eligibility Question |
| Households in which all members receive or are authorized to receive FA, SNA and/or SSI benefits shall be eligible for FS because of their status as FA, SNA and/or SSI recipients. This means that the FS resource limit and the food stamp gross and/or net income limits are not applied as eligibility criteria to such households. | Not in the form of eligibility question — questions for all tools in question based upon computing categorical eligibility from answers to questions about income, assets, dependent care costs, etc. |
Policy Rules Database
Policy Engine
None of the screening tools base their determination of categorical eligibility purely on whether or not an individual self-reports being a recipient of one of the programs that would make them eligible for SNAP. Instead, a user’s answers to the eligibility questions are used to compute whether the individual is eligible for benefits that would also make them eligible for SNAP. Therefore, categorical eligibility appears to often be treated in the same manner as a standard eligibility threshold rule.
The different approaches for coding these rules provide insight into potential methods for standardization. As can be seen in the examples above, even within a single organization, details such as variable names are handled very differently. The Policy Rules Database, for example, uses both camel case (eg: GrossIncomeEligibility) and snake case (eg: not_categ_elig_ssi). While this does not impede functionality, it is not generally considered a best practice as it has a high chance of errors.
On a broader scale, we can see that there is a disparity between organizations in terms of how modular the code is, and where in the process a value is computed. For example, organizations such as PolicyEngine use more complicated tests for eligibility criteria, while the 18F prototype approach involves simpler tests that are or are not called, depending on the specific household information. This leads to redundant code that could be made more modular by using functions. The same holds true across organizations. In general, many organizations are recreating the same functionality since these applications have been developed independently, in a grassroots way, rather than around a standardized framework.
Even when an organization has a publicly available repository with code that can be extended for a particular use case, they rarely have public APIs. The end result is the need to recreate the work within a new project, rather than being able to hit an endpoint to retrieve the information in question and build the desired extended functionality. Supported collaboration and standardized rules syntax with open APIs could improve efficiency and interoperability.
Call to Action
Our goal has always been to encourage and enable all federal and state policy guides to be published in plain language. We also believe that government organizations should make companion communication available in an open source data standard and syntax for U.S. benefits eligibility rules, with the potential to be distributed and accessed via an open API.
Framework Investigation
Over the coming months, we seek collaboration to create a shared framework. We will be asking the grassroots community and levels of government the following:
- Which of the existing frameworks have the most potential?
- What is missing from the existing frameworks?
- How do we further pressure test existing frameworks?
- What operational changes are needed to publish rules as code?
- What operational changes are needed to absorb rules as code?
Continued Research
We are continuing our research into benefits eligibility rules as code, with a focus on understanding the barriers and enablers present at every level of implementation. Going forward, we will be:
- Analyzing state, territorial, tribal, and local government eligibility and enrollment systems to better understand how these systems write, store, and utilize digitized rules. This includes examining where coded rules are used in automations to help advance determinations or make recommendations.
- Seeking to understand and encourage the documentation of the processes used for writing rules into code in demonstration projects in the U.S. and internationally, including exploring the implications of ambiguous language in law, regulation, and policy for digitization into code.
Proof of Concept is Key
We are exploring how to create a proof of concept and build on the research and work already happening in the rules as code community. The anticipated pilot project will test a rules as code approach to multiple federal benefits programs in several states, territories, tribes, counties, or municipalities, with participation from several delivery organizations. This future proof of concept will have built in measurement and evaluation to identify what works. Once we have an answer we can predict and demonstrate what can be scaled into a national approach. The resulting recommendations will include design, process, technical, and procurement elements.
Get in Touch
We’re eager to hear from you! This work, like any public-facing project, gets better as more stakeholders chime in and get involved. Please contact us with your thoughts, questions, or potential collaborations. Reach us via email at digitalgovhub@georgetown.edu.
Acknowledgments
We’d like to acknowledge and thank SNAP Screener, Federal Reserve Bank of Atlanta, PolicyEngine, Benefits Data Trust, mRelief, Arizona Department of Economic Security, 18F, NYC Mayor’s Office for Economic Opportunity, Open Referral, and Benefits Kitchen for sharing insights into their work for this brief.
Citation
Cite as:
Kennan, Ariel, Lisa Singh, Bianca Dammholz, Keya Sengupta, and Jason Yi. “Exploring Rules Communication: Moving Beyond Static Documents to Standardized Code for U.S. Public Benefits Programs”, June 6, 2023.